Student Wellness
Analyzing student survey data on sleep and stress.
Project Overview
This project originated in an undergraduate Data Science course and served as my first deep dive into the full product development lifecycle. The goal was to analyze survey data collected from ~90 FSU students to find potential patterns in the data during midterms.
This project is a showcase of my foundational data analytics skills, including data cleaning, preparation, and visualization. It demonstrates a strong attention to detail regarding data integrity and the realities of working with imperfect datasets.
My Role & Methods
As the Data Analyst for this project, I was responsible for the entire process: defining the research question, cleaning and preparing the raw data, analyzing it for correlations, and visualizing the findings.
The methods were chosen to suit a purely quantitative analysis of pre-existing survey data.
- Data Cleaning (Excel): This was the most critical method. The raw Google Forms data was filled with inconsistent text, duplicates, and irrelevant entries. Excel was the ideal tool for meticulous, cell-by-cell standardization.
- Data Analysis (Excel): Pivot Tables were used as the primary analysis tool to quickly segment the data (Strategy vs. No Strategy) and compare descriptive statistics across multiple metrics.
- Data Visualization (Looker Studio): While Excel can create charts, Looker Studio was chosen to build a more dynamic, professional, and shareable dashboard to present the final findings.
The data collected featured a lot of different metrics, but I chose to focus on sleep strategy as the key independent variable. The rationale was that sleep is a well-known factor influencing stress and productivity, making it a logical focal point for analysis.
Do students with a defined sleep strategy report significantly different sleep duration, stress levels, and daily productivity indicators compared to students without a strategy?
Methodology
My approach followed a standard data analysis process: Gather, Question, Identify, Model, and Conclude.
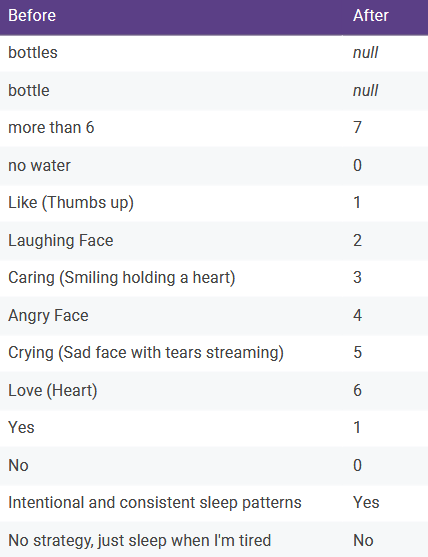
Data Cleaning & Preparation
Preparing the raw survey data for analysis was crucial. This involved several steps using Microsoft Excel:
- Standardization: Used "Find and Replace" and
IFfunctions to convert text-based responses (e.g., "Like (Thumbs up)", "no water") into numerical or consistent categorical values (e.g., 1, 0). - Duplicate Removal: Used the
EXACTfunction and conditional formatting to identify and remove duplicate submissions. - Filtering: Removed irrelevant data, such as entries outside the collection window and participants with fewer than 3 daily submissions, to ensure a baseline of data quality.
- Segmentation: Created the two primary analysis groups ("Sleep Strategy" vs. "No Sleep Strategy") based on closing survey responses.
Analysis & Visualization
I used Excel Pivot Tables for initial comparative analysis and Looker Studio for the final dashboard visualizations. The analysis focused on comparing descriptive statistics for the two core segments (Sleep Strategy vs. No Strategy) across key daily metrics.
Key Findings & Visualizations
The analysis revealed some interesting patterns, but ultimately did not support my initial hypothesis with strong, conclusive evidence.
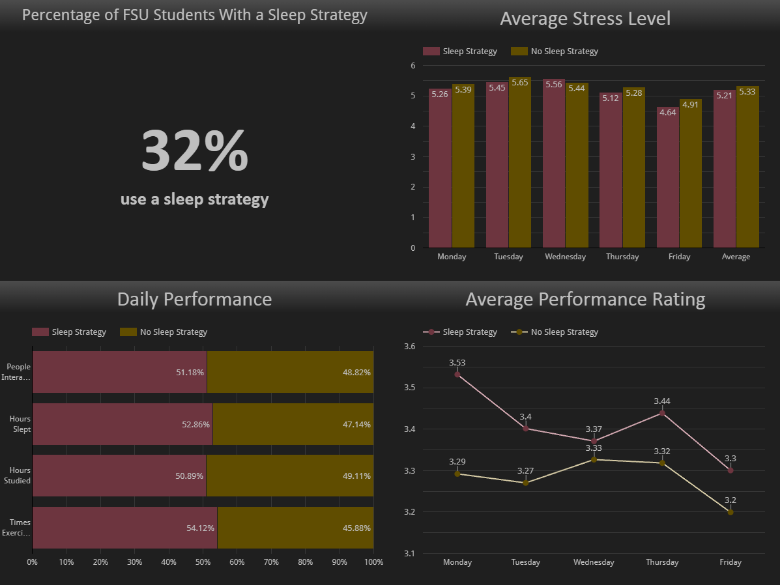
- Low Adoption: Only 32% of students reported using a consistent sleep strategy.
- Minor Stress Level Differences: Students with a sleep strategy reported slightly lower average stress (5.21 vs. 5.31), but the difference is not statistically significant.
- Slightly Higher Performance: Similarly, students with a strategy self-reported slightly higher daily performance (3.44 vs. 3.30).
Conclusion & Key Limitations
The data suggests a weak positive correlation between having a sleep strategy and reporting lower stress or higher performance. However, the findings were not conclusive.
This project's most valuable outcome was not the finding itself, but the lesson in data integrity. The primary limitation, which I identified during reflection, was the reliance on self-reported data.
- Subjectivity: "Stress level" is deeply subjective. A "5" for one student is not the same as a "5" for another. This introduces significant noise into the data.
- Recall Bias: The data was collected during midterms, a period of high stress for everyone, which likely skewed the results and made it difficult to isolate the effect of a sleep strategy.
Reflection
As my first formal data analysis project, this was an irreplaceable learning experience. It taught me that the data cleaning phase is arguably the most important, as "garbage in, garbage out."
Most importantly, it taught me to be critical of my data sources and to acknowledge when findings are inconclusive. Recognizing that my hypothesis was not strongly supported due to flawed data collection (i.e., relying on self-reported stress) was a key insight. A stronger future study would need to incorporate more objective measures of stress or performance.